
| In English | Accueil/Contact | Billard | Bélier | SNH | Relativité | Botanique | Musique | Ornitho | Météo | Aide |
Les produits de consommation courante ou durable proposés sur les marchés n'ont pas toujours la qualité attendue. Les principales causes sont les suivantes :
F1.1. Vice de "construction" du produit
Trois types de défaut existent :
En France, près de 10 % des appareils électroniques achetés sur Internet sont retournés pour cause de non-conformité.
Pour les appareils domestiques électriques, le composant en défaut est souvent le bloc électronique de l'appareil (exemples : congélateur, fer à centrale vapeur, thermorésistance des sèche-serviettes, éclairage des armoires de toilette à commande tactile, guirlande lumineuse extérieure solaire, lecteur de DVD).
F1.2. Manuel utilisateur non optimal
Le manuel utilisateur du produit est parfois succinct, mal structuré, traduit approximativement en français ou écrit uniquement en anglais, ne permettant pas aux consommateurs d'utiliser le produit facilement et avec pertinence.
F1.3. Service consommateur non optimal
L'accès au service consommateur n'est pas toujours simple (exemples : modes d'accès pas clairs, numéro téléphonique surtaxé, temps d'attente non spécifié).
Par ailleurs, le traitement des demandes et des réclamations est parfois déconcertant voire défaillant, certains opérateurs n'ayant pas toujours une formation suffisante aux produits et services du catalogue, aux procédures internes et aux outils informatiques.
F1.4. Obsolescence prématurée ou programmée du produit
L'obsolescence programmée est une pratique de marché justifiée par les fabricants par des raisons économiques (voir Société de consommation), techniques et de prévention des risques. Le consommateur en subit les conséquences : il est frustré quand il constate que la durée de vie effective de son produit ne correspond pas à la durée de vie qu'il attend.
Mais les causes de l'obsolescence ne sont pas uniquement liées au producteur. Elles peuvent intervenir lors de la vente, de la distribution ou de la consommation. C'est pourquoi on parle plus largement d'obsolescence prématurée.
Différents types d'obsolescence prématurée peuvent écourter la durée de vie des produits de consommation [CLI][HIP] :
La France est le premier pays du monde à avoir érigé l'obsolescence programmée en délit à travers l'article L. 441-2 du Code de la consommation en date du 14 mars 2016.
La loi n 2021-1485 du 15 novembre 2021 relative à la Réduction de l'Empreinte Environnementale du Numérique en France (loi REEN) a ensuite modifié cet article en redéfinissant le délit comme suit : "Est interdite la pratique de l'obsolescence programmée qui se définit par le recours à des techniques, y compris logicielles, par lesquelles le responsable de la mise sur le marché d'un produit vise à en réduire délibérément la durée de vie".
Attention : il peut y avoir "obsolescence" sans que celle-ci soit programmée. C'est au consommateur d'apporter la preuve de l'intention volontaire du fabricant de réduire la durée de vie du produit : tâche difficile voire impossible.
Une des solutions visant à combattre l'obsolescence programmée est la location de services. Au lieu d'être propriétaire d'un bien, on paierait pour le service rendu. Les entreprises gagneraient alors à fabriquer des biens durables et facilement réparables (exemple : Xerox sur le marché des photocopieurs professionnels) [WIK].
F1.5. Sources relatives à l'obsolescence programmée :
[HIP] HIPPOCAMPE, Usages numériques et terminaux.
[CLI] LE CLIMATOSCOPE, L'obsolescence prématurée de nos produits de consommation : un débat à remodeler.
[WIK] WIKIPEDIA, Obsolescence programmée.
La société de consommation est un type de société au sein de laquelle les consommateurs sont incités à consommer des biens et des services de manière régulière et abondante [JDN].

F2.1. Introduction :
La société de consommation est apparue dans les pays occidentaux à partir de la seconde moitié du 20e siècle, en même temps que certains courants comme l'émancipation de la femme, l'innovation industrielle et technologique, la mondialisation des échanges.
L'économie va alors se reposer sur les capacités de production des entreprises ainsi que sur celles de consommation des citoyens. Elle va accroître le niveau de vie d'un grand nombre de citoyens en termes de confort et de bien-être matériel, en augmentant l'accès à des biens et services en volume et en diversité.
Mais progressivement un nouveau paradigme voit le jour : "consommer plus, produire plus, gagner plus". Producteurs et consommateurs deviennent alors mécaniquement des hyper-producteurs et des hyper-consommateurs. Les premiers proposent une offre abondante basée sur des produits à durée de vie limitée (Obsolescence prématurée). Les seconds ont des exigences dépassant largement leurs besoins primaires.
F2.2. Conséquences :
Cette situation, où producteurs et consommateurs sont intimement liés autour de l'industrie du "désir", a abouti aux conséquences suivantes sur l'individu et son environnement :
1. Sur le plan de l'information, les médias (presse, édition, affiche, radio, télévision, cinéma, réseau Internet, télécommunications) diffusent au consommateur (lecteur, auditeur, spectateur, internaute) une masse d'informations plus ou moins exactes, amplifiée par les réseaux sociaux et les plateformes de partage de contenu.
La diffusion peut prendre différentes formes :
2. Sur le plan de la communication audiovisuelle, les médias, dont le souci est avant tout de préserver un marché plutôt que de veiller à l'éducation citoyenne des masses, deviennent source de pollution sensorielle et de surstimulation des sens au détriment de l'information utile [BEN]. Voir Violence médiatique.
3. Sur le plan écologique, la surconsommation favorise le gaspillage et la production de déchets qui polluent, même si des progrès sont faits pour les recycler le plus proprement possible.
4. Sur le plan nutritionnel, la surconsommation favorise l'apparition de pathologies comme le diabète et l'obésité.
5. Sur le plan professionnel, la création perpétuelle de nouveaux besoins peut mener au surendettement, surmenage ou précarité.
6. Sur le plan psychologique, la recherche du "toujours plus" peut entraîner une continuelle frustration qui engendre mal-être, comportements dépressifs voire agressifs.
7. Sur le plan social, l'être humain est devenu lui aussi un "produit" qui doit "savoir se vendre", qui doit entrer "en concurrence", "en guerre" avec tous et autrui.
8. Sur le plan moral, les objets de consommation deviennent des fins en soi entraînant une perte de "véritable finalité".
9. Sur le plan humain, les relations sociales deviennent de simples moyens et sont par là même artificielles. Il faut alors se différencier des autres, notamment en épatant autrui par des symboles de richesse et de puissance au détriment de l'authenticité et de la profondeur des relations humaines.
10. Sur le plan spirituel, l'avoir se substitue à l'être, à la profondeur, à l'introspection, à une réflexion sur l'identité fondée sur autre chose que les possessions [GUI].
F2.3. Conclusions :
Aujourd'hui, la société de consommation, devenue société de surconsommation, commence à se diriger vers une société de déconsommation selon quatre axes : individuel, communautaire, systémique et environnemental :
1. Sobriété individuelle qui consiste à consommer moins et autrement, en privilégiant qualité plutôt que quantité.
Pour être applicable au niveau de chaque consommateur, cette sobriété doit être "heureuse", c'est-à-dire sans idée de restriction ou de sacrifice. En exemples : achat d'occasion, recours à la réparation, retour à des besoins essentiels.
Cette tendance serait portée en France par les personnes âgées (ayant moins de besoins), les femmes (attirées vers l'écologie) et les plus diplômés (attirés vers une forme d'ascétisme au quotidien) [GOL][CAS].
2. Economie collaborative basée sur le partage ou l'échange entre particuliers de biens (voiture, logement, parking, perceuse, etc.), de services (transport de passagers, bricolage, etc.) ou de connaissances (cours d'informatique, communautés d'apprentissage, etc.), avec ou sans échange monétaire, avec ou sans plateforme numérique de mise en relation.
En diminuant, voire en supprimant les intermédiaires, ce système économique permet de modérer ses dépenses et de faire des économies.
3. Economie circulaire tournée vers une stratégie durable qui consiste à partager, réutiliser, réparer, rénover et recycler les produits et les matériaux le plus longtemps possible afin qu'ils conservent leur valeur.
En France, on peut citer les exemples suivants :
4. Gestion des déchets qui consiste à les collecter puis les transformer en privilégiant dans l'ordre : la réutilisation, le recyclage, l'élimination [MTE].
En France, en 2018, 66 % des déchets traités sont recyclés, 7 % sont incinérés avec ou sans récupération d'énergie et 27 % sont mis en décharge [NOT].
F2.4. Sources relatives à la société de consommation :
Sources relatives à la à la société de consommation :
[ADE1] ADEME, Economie circulaire : notions, 2013.
[ADE2] ADEME, Potentiels d'expansion de la consommation collaborative pour réduire les impacts environnementaux, 2016.
[AGE] Agence Lucie, L'économie circulaire.
[ALT] Altermaker, Economie circulaire : définition et exemple.
[BEN] Abdellatif Bensfia, "François HEINDERYCKX (2003), La malinformation. Plaidoyer pour une refondation de l'information", Communication, Vol. 23/2 | 2005, 259-265..
[CAS] Jean-Laurent Cassely, Les diplômés, bons élèves ou cancres de l'alterconsommation ?, in Constructif, juin 2021 (N 59).
[CHI] Chilowé, Comment vivre la sobriété heureuse au quotidien ?.
[DES] Cécile Désaunay, Vers la déconsommation ?, in Constructif, juin 2021 (N 59).
[GOL] Mathilde Golla, La société de déconsommation commence à faire son chemin, Novethic.
[GUI] Valérie Guillard, La société de consommation, cours PSL Paris-Dauphine.
[IMP] impots.gouv.fr, Economie collaborative et plateformes numériques.
[JDN] JDN - Journal du Net, Consommation : définition simple.
[MAR] Margaux, Société d'hyperconsommation : comment en sommes-nous arrivés là ? Comment changer demain ?, Suricates Consulting.
[ODI] ODI - Observatoire de la Déontologie et de l'Information, L'information au coeur de la démocratie - Rapport Annuel 2017.
[RUM] Yannick Rumpala, Quelle place pour une "sobriété heureuse" ou un "hédonisme de la modération" dans un monde de consommateurs ?, in Dans L'Homme & la Société 2018/3 (n 208), pages 223 à 248.
[TOU] La Toupie, Toupictionnaire.
[WIK1] Wikipedia, Société de consommation.
Sources relatives à la gestion des déchets :
[ADE3] ADEME, Déchets chiffres-clés - Edition 2023.
[MTE] Ministère de la transition écologique et de la cohésion des territoires, Traitement des déchets.
[NOT] notre-environnement, Le traitement des déchets.
[REC] Recygo, Poubelles de tri sélectif, comprendre les codes couleurs.
[SEN1] Sénat, Les nouvelles techniques de recyclage et de valorisation des déchets ménagers et des déchets industriels banals.
Un sondage est, par définition, une méthode statistique d'analyse d'une population à partir d'un échantillon de cette population.
Il est principalement utilisé à des fins politiques (pour aider à la prise de décision), électorales (pour exister dans le paysage politique), commerciales (pour anticiper les ventes d'un produit ou connaître la satisfaction de la clientèle), militantes (pour défendre une cause) ou médiatiques (pour faire de l'audience).
La qualité de l'information recueillie dépend largement de la rigueur entourant la conception et la réalisation du sondage, ainsi que de l'interprétation des résultats.
Les paramètres importants d'un sondage sont les suivants :

F3.1. Taille de l'échantillon [GUM][SER][PER][WIK2] :
La taille de l'échantillon est un facteur déterminant pour obtenir des résultats fiables.
La formule suivante (formule de Cochran) détermine le nombre de personnes (n) à interroger en fonction de la marge d'erreur (m) que l'on peut tolérer sur une proportion attendue de réponses (p).
n = z2 x p (1 - p) / m2
p est la proportion attendue de réponses par rapport à la taille n de l'échantillon (lorsque p est inconnue, on utilise p = 0,5).
m est la marge d'erreur tolérée sur la proportion p, l'intervalle de confiance valant [p - m, p + m].
NC est le niveau de confiance (ou probabilité) que les réponses se trouvent dans la marge d'erreur (m).
z est le quantile d'ordre α/2 de la loi normale centrée réduite pour un niveau de confiance donné NC = 1 - α (z = 1,96 pour NC = 95 %, z = 2,58 pour NC = 99 %).
Avec un niveau de confiance de 95 % et une marge d'erreur de 5 %, le calcul donne : n = 384,16
Avec un niveau de confiance de 99 % et une marge d'erreur de 2 %, le calcul donne : n = 4144,14
Pour une étude de marché suffisamment fiable, on admet le plus souvent un niveau de confiance de 95 % et une marge d'erreur de 5 %, ce qui nécessite d'interroger 400 personnes.
A noter que la marge d'erreur ne tient compte que de l'erreur aléatoire, c'est-à-dire les différences possibles entre échantillon et population de référence du seul fait du hasard de l'échantillonnage [TOU]. Elle ne tient pas compte de toutes les autres erreurs (représentativité de l'échantillon, qualité du questionnaire, conduite du sondage, analyse des résultats).
|
Démonstration de la formule de Cochran [WIK1][WIK2][WIK3] : On cherche à estimer la proportion réelle (p) d'une population susceptible de répondre positivement à un questionnaire. Pour cela, on réalise un sondage sur une population restreinte en soumettant le questionnaire à un nombre (n) d'individus tirés au hasard. On suppose que le sondage est basé sur un échantillon aléatoire simple d'une grande population. Si on répète plusieurs fois l'opération, la proportion de réponses obtenue suit alors une loi binomiale de moyenne p et d'écart-type σ = (p (1 - p) / n)1/2 Pour n suffisamment grand, cette loi binomiale est très proche d'une loi normale de moyenne p et d'écart-type σ Pour obtenir la marge d'erreur (m) sur la proportion p, on multiplie simplement l'écart-type σ par le facteur z de la loi normale centrée réduite pour un niveau de confiance donné (NC), ce qui donne : m = z σ = z (p (1 - p) / n)1/2 D'où la formule : n = z2 x p (1 - p) / m2 A noter que la marge d'erreur est maximale pour p = 0,5 |
F3.2. Représentativité de l'échantillon :
L'échantillon doit être représentatif de la population de référence si on veut extrapoler les résultats du sondage à l'ensemble de la population.
- S'il s'agit d'un sondage aléatoire réalisé à partir d'un échantillon tiré au hasard sur l'ensemble de la population, il faut s'assurer que la base d'échantillonnage est complète, à jour et sans répétition, et contenant toutes les catégories de la société (origine, sexe, âge, profession, région, etc.) [GUM][LAL]. C'est la méthode utilisée par exemple pour les grandes enquêtes menées par l'Insee [TOU].
- S'il s'agit d'un sondage par sélection avec choix judicieux (méthodes des quotas), il faut s'assurer que les quotas sont sensiblement proportionnels à la fraction de la population représentée par chaque catégorie. Cette option est privilégiée par les instituts de sondages en France et appliquée à des échantillons bien plus faibles, généralement 1000 ou 2000 personnes [TOU].
- Les sondages par Internet permettent d'interroger un grand nombre de personnes à faible coût. Toutefois, les listes de courriels ne sont généralement pas représentatives et 20 % de la population, non "branchée Internet", est omise [LAL].
F3.3. Clarté du questionnaire :
- Indiquer le temps estimé total pour répondre au questionnaire, lequel ne doit pas être trop long au risque de lasser le participant.
- Limiter le questionnaire à 15 questions et chaque question à un seul sujet comportant 20 mots maximum. Par exemple, demander "Comment évaluez-vous la qualité de notre produit et de notre service client ?" amène à une confusion qui pousse à ignorer la question.
- Eviter les questions sensibles liées notamment à l'argent, la religion, l'intimité, la sexualité ou les conflits familiaux.
- Adapter le vocabulaire à celui de la population interrogée. Par exemple, la question "La France consacre environ le quart du revenu national au financement de la protection sociale. Considérez-vous que c'est excessif, normal ou insuffisant ?" peut être simplifiée avantageusement par la question "Pensez-vous que l'on dépense assez pour la protection sociale ?".
- Donner une définition des sigles, des mots techniques et des mots peu usités.
- Ne pas utiliser de mots restrictifs tels que "toujours, "jamais", "tout" ou "aucun", qui empêchent les personnes de nuancer leur propos et de répondre objectivement.
- Ne pas poser de questions imprécises, comme par exemple : "Avez-vous été récemment au cinéma ?" ou "Combien consommez-vous en moyenne d'essence ?".
- Ne pas poser de questions basées sur des affirmations, comme par exemple : Etes-vous d'accord avec l'affirmation "La police ne devrait pas intervenir" ?
- Ne pas poser de questions contenant des superlatifs ou des adjectifs subjectifs, voire chargés d'émotion ou controversés, comme par exemple : "Notre service clients a-t-il été excellent ?" ou "A quel point votre séjour dans notre hôtel a-t-il été incroyable ?".
- Ne pas poser de questions contenant des mots impliquants, comme par exemple : "Avez-vous peur du bruit dans votre résidence ?" ou "Etes-vous impatient de découvrir notre nouvelle boutique en ligne ?".
- Ne pas poser de questions contenant des tournures négatives, comme par exemple : "Préférez-vous ne pas utiliser les vélos à assistance électrique dans le cadre de vos promenades à vélo ?".
- Ne jamais utiliser de double négation comme par exemple : "Selon vous, l'utilisation du glysophate n'est-il pas sans danger ?".
F3.4. Efficacité du questionnaire :
- Préférer les questions fermées (choix unique ou choix multiples, à sélectionner parmi une liste d'options) aux questions ouvertes (recueil d'avis), ces dernières induisant une exploitation statistique longue et difficile des réponses.
- A chaque question fermée, limiter le nombre d'options, sans oublier l'option "Non concerné" ou "Sans opinion".
- Eviter les options imprécises, comme "habituellement" ou "souvent", à remplacer par une notion claire comme par exemple "tous les jours" ou "plus de 2 fois par semaine".
- Eviter le choix unique binaire "Oui"/"Non" qui amène les personnes à répondre de manière moins réfléchie et favorise la réponse "Oui" pour paraître plus agréable (biais de positivité ou tendance à l'acquiescement [JAC][SOU]). Proposer plutôt un choix unique entre deux possibilités de réponse ou plus.
- Pour les choix uniques à plus de 2 options, préférer le choix à 4 options équilibrées, comme par exemple : "Très satisfait", "Satisfait", "Insatisfait", "Très insatisfait".
- Pour les choix uniques à plus de 2 options constituées de plages, s'assurer qu'elles s'excluent mutuellement, comme par exemple : "2 ans ou moins", "3 à 5", "6 ou plus".
- Pour les choix uniques à plus de 2 options constituées de notes (1 à 4 par exemple), mentionner explicitement que la note 1 correspond à la note la plus basse.
- Pour les choix multiples, les classer par ordre alphabétique, sans oublier l'option "Autre".
- Ajouter des informations contextuelles pour expliquer et guider le participant dans ses réponses.
F3.5. Neutralité du questionnaire :
Il faut n'accordez crédit qu'aux sondages dont les questions sont les plus neutres possible. Certaines questions appellent la réponse. Par exemple [LAL] :
- Si l'on demande "Préférez-vous utiliser l'ancienne version ou cette version améliorée du site internet ?", il s'agit d'une question biaisée puisque la question induit par le mot "améliorer" que la dernière version du site est meilleure.
- Si l'on demande " Pensez-vous que les compagnies aériennes doivent autoriser l'utilisation du téléphone cellulaire en vol ?", les réponses ne seront pas les mêmes que si l'on demande " Pensez-vous que les compagnies aériennes doivent interdire l'utilisation du téléphone cellulaire en vol ?"
- Si l'on demande "Trouvez-vous important que les règles de sécurité dans les aéroports soient resserrées ?", la plupart des gens répondront par l'affirmative. Toutefois, si on leur fait part des modalités qui accompagneront cette plus grande sécurité (attentes plus longues, présence policière accrue, augmentation du coût des billets, etc.), leur avis sera peut-être différent.
- Si l'on demande "Etes-vous favorable ou défavorable à ce que l'on sanctionne les juges en cas de faute ayant entraîné une erreur judiciaire ?", qui ne voudrait pas sanctionner quelqu'un ayant commis une faute ?
F3.6. Conduite du sondage :
Lorsque le sondage s'effectue sur le "terrain" (en face-à-face ou par téléphone), il faut s'assurer que :
- les enquêteurs sont sérieux, professionnels, bien formés, d'apparence neutre, accueillants et relationnels.
- le lieu, le moment et les circonstances sont propices. Par exemple, ne lancer le sondage que lorsque le contexte médiatique est relativement neutre par rapport au sujet du sondage.
- le participant est disponible pour répondre au questionnaire.
F3.7. Analyse des résultats :
La compréhension et l'interprétation des résultats sont parfois très différentes selon l'analyste. Par exemple [LAL] :
- Si l'on demande à des voyageurs d'affaires "Utilisez-vous souvent, à l'occasion, rarement ou jamais l'accès Internet dans votre chambre d'hôtel ?", les résultats différeront grandement selon les regroupements que l'on fera des réponses. Le résultat "oui" correspondant au cas "souvent" intègre-t-il aussi le cas "à l'occasion", voire le cas "rarement" ?
- Si les résultats montrent que "60 % des Canadiens utilisent leur carte de crédit pour payer leurs vacances", alors il ne faut pas condenser l'information sous la forme "Les Canadiens voyagent à crédit".
F3.8. Redressement des résultats [DAN] :
Le redressement est une pratique courante dans l'univers des sondages.
Il consiste à appliquer des pondérations aux individus pour augmenter le poids de ceux appartenant à des catégories sous-représentées dans l'échantillon interrogé par rapport à la population de référence, et à réduire parallèlement le poids de ceux qui sont sur-représentés.
Le redressement sur une seule variable correspond à une simple règle de 3. Le redressement sur plusieurs variables en même temps est plus complexe et nécessite de longs calculs sur ordinateur.
Mais attention, des pondérations trop importantes font courir un risque certain à la qualité des résultats. Ainsi, il semble aberrant de donner un poids 10 fois plus important aux réponses de la seule personne que l'on a réussi à interroger dans une catégorie donnée.
Il se peut également que les calculs ne permettent pas de faire converger l'échantillon interrogé vers la distribution recherchée.
Ainsi, si des données sont fausses dès le départ, qu'elles ont été mal collectées, mal saisies, ou qu'elles comportent trop de données manquantes, il ne servira à rien de chercher à redresser.
D'où l'extrême importance de veiller à obtenir en amont des échantillons cohérents avec la population de référence.
F3.9. Publication des résultats :
Tout sondage publié doit être accompagné de certaines informations.
La loi française du 19 juillet 1977 encadre les sondages rendus publics sur le territoire national et liés au débat électoral. Ils doivent mentionner a minima l'objet du sondage, le nom de l'organisme, le nom du commanditaire, le nombre de personnes interrogées, la date, le libellé exact des questions posées et la proportion de "sans réponse" [DOC].
F3.10. Fiabilité des sondages :
Concernant la fiabilité des sondages, les avis sont partagés :
Pour certaines personnes, malgré leurs défauts, les sondages sont de bons révélateurs de tendances et d'opinions [LAL]. Ils ne se trompent pas quand ils sont bien faits et qu'on les observe de façon tendancielle.
Pour d'autres, les sondages reflètent une opinion formulée sur le vif. Répondre à un sondeur n'engage à rien. Cela peut être même l'occasion de jouer, voire d'exprimer sa colère du moment.
Les sondages reflètent également une opinion noyée dans le bruit médiatique autour de la question posée.
Mais le plus souvent, le sondage est utilisé pour faire de l'audience. Sa pertinence n'est quasiment jamais évoquée.
Seules les enquêtes en profondeur, répétées d'années en années, ont un intérêt pour comprendre les évolutions des valeurs sur le long terme [COS].
F3.11. Sources relatives aux sondages :
[COS] Centre d'observation de la société, Le sondage - un mauvais outil pour comprendre la société.
[DAN] Gérard Danaguezian, Le redressement d'échantillons, Survey Magazine.
[DOC] Doctrine, Loi n 77-808 du 19 juillet 1977 relative à la publication et à la diffusion de certains sondages d'opinion.
[GUM] Hervé Gumuchian et Claude Marois, Chapitre 6 - Les méthodes d'échantillonnage et la détermination de la taille de l'échantillon, in Initiation à la recherche en géographie, Presses de l'Université de Montréal.
[JAC] Marc Jacquemain, Méthodologie de l'enquête, Institut des Sciences Humaines et Sociales, Université de Liège.
[LAL] Michèle Laliberté, L'art des sondages ou comment éviter les pièges, Réseau Veille Tourisme.
[PER] Anne Perrut, Cours de probabilités et statistiques.
[SER] Zineb Serhier, Comment calculer la taille d'un échantillon pour une étude observationnelle ?.
[SOU] Dr. Ghomari Souhila, Techniques d'Enquête, Université de Tlemcen.
[TOU] Hugo Touzet, Connaître et mesurer l'opinion publique : utilité et limites des sondages, Ressources en Sciences Economiques et Sociales.
[WIK1] Wikipedia, Intervalle de confiance.
[WIK2] Wikipedia, Marge d'erreur.
[WIK3] Wikipedia, Loi normale.
Lorsqu'on dispose d'un jeu de données, issues par exemple de nombreuses mesures, il est souvent utile de le caractériser par des paramètres de tendance centrale (comme la moyenne arithmétique ou la médiane) et de dispersion (comme l'écart-type ou l'écart interquartile).
Il est important aussi de connaître l'influence des données aberrantes sur ces paramètres.
Enfin, la méthode statistique réserve un certain nombre de pièges dans lesquels même des utilisateurs expérimentés peuvent tomber.
Considérons une liste de n données xi, l'indice i allant de 1 à n. Les paramètres statistiques les plus courants sont alors les suivants :
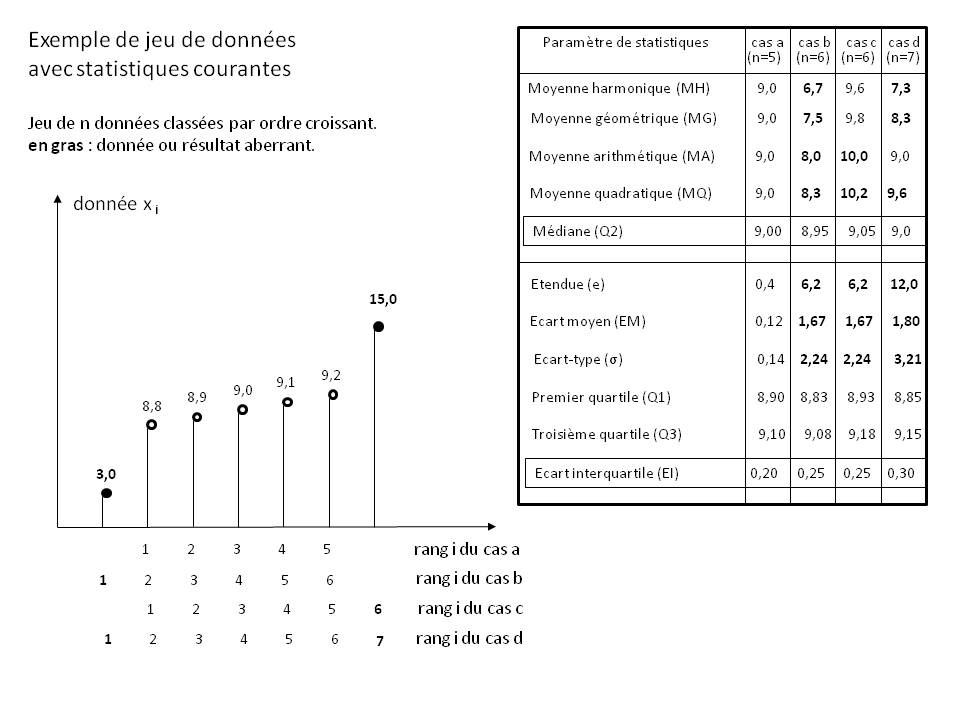
F4.1. Données aberrantes [WIK5]
Une donnée aberrante est une donnée contrastant grandement avec les autres données, de façon anormalement faible ou élevée.
La donnée aberrante est due :
- soit à une erreur de mesure, auquel cas il faut supprimer la donnée aberrante ou utiliser des indicateurs statistiques robustes face aux données aberrantes,
- soit à une distribution de données fortement asymétrique, auquel cas il faut se montrer très prudent dans l'utilisation d'outils ou de raisonnement conçus pour une distribution normale.
Différentes méthodes existent pour identifier les données aberrantes présentes dans un jeu de données.
La plus simple [KHA] consiste à classer les données par ordre croissant puis à identifier le premier quartile (Q1), le troisième quartile (Q3) et l'écart interquartile EI = Q3 - Q1.
Sera alors considérée comme aberrante toute donnée xi vérifiant l'une des relations suivantes :
xi < Q1 - 1,5 EI ou xi > Q3 + 1,5 EI
La Figure ci-dessus montre un exemple de jeu de données comportant des données aberrantes (indiquées en police grasse).
Le tableau de droite montre l'influence de ces données aberrantes sur le calcul des différents paramètres statistiques courants pour quatre cas particuliers :
cas a : jeu de 5 données sans aucune aberrante
cas b : jeu de 6 données comportant celles du cas a complétées par une donnée anormalement faible
cas c : jeu de 6 données comportant celles du cas a complétées par une donnée anormalement élevée
cas d : jeu de 7 données comportant celles du cas a complétées par les données aberrantes des cas b et c
L'analyse de ce tableau est donnée ci-dessous pour chaque paramètre statistique.
F4.2. Paramètres de tendance centrale
Les principaux paramètres de tendance centrale sont les suivants, dont la médiane qui est robuste aux données aberrantes.
Moyenne généralisée Mp [WIK2] :
Pour n données xi strictement positives, la moyenne généralisée d'ordre p non nul (ou moyenne de Hölder) est la quantité : Mp = ( (1/n) ∑i[xip] )(1/p)
Cette moyenne est utilisée en pratique avec :
p → -∞ pour le minimum des données Min{xi}
p = -1 pour la moyenne harmonique MH
p → 0 pour la moyenne géométique MG
p = 1 pour la moyenne arithmétique MA
p = 2 pour la moyenne quadratique MQ
p → +∞ pour le maximum des données Max{xi}
Entre différentes moyennes, on a la relation suivante : Min{xi} ≤ MH ≤ MG ≤ MA ≤ MQ ≤ Max{xi}
La moyenne généralisée ne dépend pas de l'ordre des données.
La moyenne généralisée est homogène : pour toute constante k strictement positive, on a la relation : Mp(k xi) = k Mp(xi)
La moyenne généralisée est cumulative : si la liste de données est partagée en plusieurs sous-listes, la moyenne de la liste globale est la moyenne pondérée des moyennes des sous-listes, avec pour coefficients de chaque sous-liste le nombre de termes concernés.
La moyenne généralisée peut s'exprimer sous forme de norme d'ordre p : Mp(x1, x2... xn) = (1/n)1/p) ||(x1, x2... xn)||p
|
Démonstration de la moyenne généralisée pour p → 0 [WIK3] : Pour p → 0, Mp prend la forme indéterminée 1∞ On réécrit alors Mp sous la forme : Mp = exp[X] avec : X = ln[ ( (1/n) ∑i[xip] )(1/p) ] = (1/p) ln[ (1/n) ∑i[xip] ] = f(p)/g(p) f(p) = ln[ (1/n) ∑i[xip] ] g(p) = p Ayant par ailleurs f(0) = ln[1] = 0 et g(0) = 0, on peut appliquer la règle de l'Hôpital sous réserve de l'existence de f'(p) et de g'(p) : f'(p) = ∑i[ xip ln[xi] ] / ∑i[xip] en utilisant les relations ln'(u) = u'/u et (xp)' = xp ln[x], et à condition que x soit strictement positif. g'(p) = 1 D'où (règle de l'Hôpital) : lim(p → 0)(X) = lim(p → 0)( f(p)/g(p) ) = f'(0)/g'(0) = (∑i[ 1 ln[xi] ] / ∑i[1]) / 1 = ∑i[ ln[xi] ] / n = ln[ Produiti[xi] ] / n La fonction exponentielle étant continue partout et définie en 0, on peut alors écrire : lim(p → 0)(Mp) = lim(p → 0)(exp[X]) = exp[ lim(p → 0)(X) ] = exp[ ln[ Produiti[xi] ] / n ] = (exp[ ln[ (Produiti[xi] ] ])1/n = (Produiti[xi])1/n qui est bien l'expression de la moyenne géométrique. |
|
Démonstration de la moyenne généralisée pour p → ±∞ [WIK3] : Pour les grandes valeurs de p telles que p → +∞, on peut écrire : ∑i [xip] = xmaxp ∑i [ (xi/xmax)p ] = xmaxp avec xmax = Max{xi} D'où : lim(p → +∞) ( (1/n) ∑i[xip] )(1/p) = lim(p → +∞) ( (1/n) xmaxp )(1/p) = lim(p → +∞) ( (1/n)(1/p) xmax ) = xmax Pour les petites valeurs de p telles que p → -∞, on peut écrire : ∑i [xip] = xminp ∑i [ (xmin/xi)-p ] = xminp avec xmin = Min{xi} D'où : lim(p → -∞) ( (1/n) ∑i[xip] )(1/p) = lim(p → -∞) ( (1/n) xminp )(1/p) = lim(p → -∞) ( (1/n)(1/p) xmin ) = xmin |
Moyenne harmonique MH [WIK1] :
Pour n données xi strictement positives, la moyenne harmonique est la quantité : MH = ( (1/n) ∑i[xi-1] )(-1) pouvant s'écrire aussi : 1/MH = (1/n) ∑i[1/xi]
La moyenne harmonique est à utiliser lorsque l'on cherche à moyenner une quantité qui influe selon une proportionnalité inverse dans un phénomène physique (exemple : vitesse moyenne d'un véhicule sur des parcours de même longueur).
La moyenne harmonique minimise l'écart quadratique défini par la somme ∑i[ (1/x - 1/xi)2 ]
Exemple [BIB] : vous faites une promenade à vélo. Vous commencez par escalader une côte de longueur L à la vitesse v1 = 20 km/h, puis vous redescendez cette même côte à la vitesse v2 = 30 km/h. Quelle est votre vitesse moyenne v ? Attention, ce n'est pas 25 km/h trouvé en prenant la moyenne arithmétique.
Si t1 = L/v1 est le temps mis pour monter et t2 = L/v2 le temps pour descendre, alors le temps total t = 2 L/v s'écrit : t = t1 + t2 = L/v1 + L/v2, ou encore : 2/v = 1/v1 + 1/v2
La vitesse moyenne v est donc la moyenne harmonique des deux vitesses v1 et v2, soit : v = 24 km/h.
La moyenne harmonique MH est fortement sensible aux données aberrantes lorsqu'elles sont anormalement faibles par rapport aux autres données (voir Tableau ci-dessus).
Moyenne géométrique MG [WIK1] :
Pour n données xi strictement positives, la moyenne géométrique est la quantité : MG = ( Produiti[xi] )1/n pouvant s'écrire aussi : ln[MG] = (1/n) ( ∑i[ ln[xi] ] )
La moyenne géométrique est à utiliser lorsque l'on cherche à avoir une représentation équilibrée de l'influence des données faibles et des données élevées grâce à leur transformation logarithmique.
La moyenne géométrique minimise l'écart quadratique défini par la somme ∑i[ (ln[x] - ln[xi])2 ]
Exemple [BIB] : à l'issue d'une manifestation, la police annonce x1 = 100 manifestants et les organisateurs x2 = 900. Quel est le nombre réel x de manifestants ? Attention, ce n'est pas 500 trouvé en prenant la moyenne arithmétique.
Si on suppose que la police et les organisateurs "trichent" de la même façon, alors la police annonce (x/k) manifestants et les organisateurs (x k), k étant un coefficient multiplicateur. En prenant le moyenne géométrique, on trouve alors le résultat exact : x = [(x/k) (x k)]1/2 = 300.
La moyenne géométrique MH est fortement sensible aux données aberrantes lorsqu'elles sont anormalement faibles par rapport aux autres données (voir Tableau ci-dessus).
Moyenne arithmétique MA (ou "moyenne usuelle") [WIK1] :
Pour n données xi quelconques, la moyenne arithmétique (ou "moyenne usuelle") est la quantité : MA = (1/n) ∑i[xi]
La moyenne arithmétique minimise l'écart quadratique défini par la somme ∑i[ (x - xi)2 ]
La moyenne arithmétique MA est sensible aux données aberrantes (voir Tableau ci-dessus). Elle ne doit être calculée que sur une distribution normale ou après avoir identifié et supprimé les données aberrantes.
Moyenne quadratique MQ [WIK1] :
Pour n données xi quelconques, la moyenne quadratique est la quantité : MQ = ( (1/n) ∑i[xi2] )(1/2) pouvant s'écrire aussi : MQ2 = (1/n) ∑i[xi2]
La moyenne quadratique est à utiliser lorsque l'on cherche à moyenner une quantité qui influe au carré dans un phénomène physique (exemple : vitesse moyenne d'une particule intervenant dans une énergie cinétique) ou qui inclut des valeurs oscillant autour de zéro (exemple : signal électrique).
La moyenne quadratique minimise l'écart quadratique défini par la somme ∑i[ (x2 - xi2)2 ]
La moyenne quadratique MQ est fortement sensible aux données aberrantes (voir Tableau ci-dessus).
Moyenne pondérée [WIK1] :
Lorsque les données sont affectées individuellement de coefficients mi (appelés poids), positifs et non tous nuls, les moyennes précédentes ont chacune une version pondérée comme suit :
- Moyenne généralisée pondérée : Mp = ( ∑i[mi xip] / ∑i[mi] )(1/p)
- Moyenne harmonique pondérée : MH = ∑i[mi] / ∑i[mi/xi]
- Moyenne géométrique pondérée : MG = ( Produiti[ximi] )1/∑i[mi]
- Moyenne arithmétique pondérée (ou barycentre) : MA = ∑i[mi xi] / ∑i[mi]
- Moyenne quadratique pondérée : MQ = ( ∑i[mi xi2] / ∑i[mi] )(1/2)
Si les poids sont de valeur entière, ils définissent le nombre de répétitions de chaque donnée.
Lorsque tous les poids sont égaux, la moyenne pondérée est identique à la moyenne non pondérée.
Médiane Q2 [WIK4] :
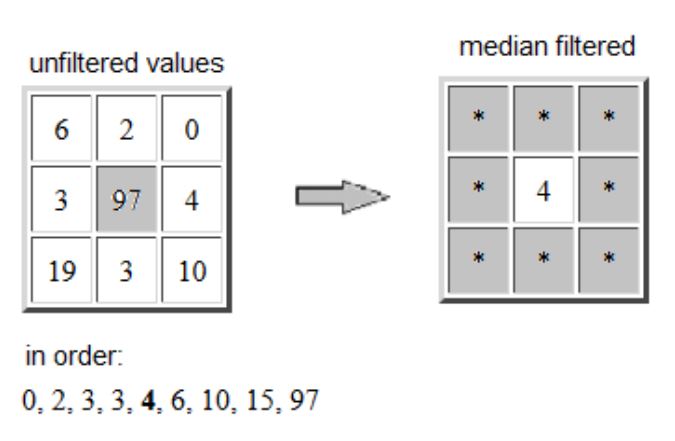
Pour n données xi quelconques, la médiane (ou second quartile) est la donnée Q2 située au milieu des données xi lorsqu'on les classe par ordre croissant [WIK6] :
- Si n est impair, alors Q2 = x(1/2)(n + 1)
- Si n est pair, alors Q2 = (1/2)(xn/2 + x(n/2 + 1))
La médiane est à utiliser lorsque l'on cherche à minimiser, voire ignorer, l'influence des données aberrantes.
La médiane minimise l'écart défini par la somme ∑i[ |x - xi| ]
Exemple : en traitement d'images numériques, le filtre médian permet de réduire le bruit tout en conservant les contours des objets de l'image. La Figure ci-dessus montre l'exemple d'un pixel aberrant (de valeur 97) remplacé par la valeur médiane (égale à 4) de son voisinage formé des huit pixels environnants.
La médiane Q2 est robuste aux données aberrantes (voir Tableau ci-dessus) et doit être préférée aux autres moyennes.
Médiane pondérée [WIK9] :
Lorsque les données sont affectées individuellement de coefficients mi (appelés poids), positifs et non tous nuls, la médiane a une version pondérée qui est la donnée xk qui partage la masse des poids en deux lorsqu'on classe les données par ordre croissant. On peut dire aussi que xk est la donnée ayant un poids cumulatif égal à la moitié de la somme de tous les poids.
k est alors solution de : ∑ i = 1, k-1 [mi] ≤ (1/2) ∑i [mi] et ∑ i = k+1, n [mi] ≤ (1/2) ∑i[mi]
Lorsque deux valeurs de k satisfont à la condition ci-dessus (k inf et k sup), alors la médiane pondérée vaut : (1/2)(xk inf + xk sup)
Si les poids sont de valeur entière, ils définissent le nombre de répétitions de chaque donnée.
Lorsque tous les poids sont égaux, la médiane pondérée est identique à la médiane non pondérée.
F4.3. Paramètres de dispersion
Les principaux paramètres de dispersion sont les suivants, dont l'écart interquartile qui est robuste aux données aberrantes.
Etendue e [WIK4] :
Pour n données xi quelconques, l'étendue (ou amplitude) est la quantité : e = Max{xi} - Min{xi}.
L'étendue e est fortement sensible aux données aberrantes (voir Tableau ci-dessus).
Ecart moyen EM [WIK4] :
Pour n données xi quelconques, l'écart moyen est la quantité : EM = (1/n) ∑i[ |xi - MA| ]
où MA est la moyenne arithmétique des données xi.
L'écart moyen est à utiliser lorsque l'on cherche à calculer la moyenne arithmétique de la valeur absolue des écarts à la moyenne arithmétique.
La fonction valeur absolue n'étant pas dérivable est parfois incompatible avec certaines analyses. Pour rendre positifs les écarts, on recourt alors à la mise au carré et on utilise l'écart-type.
L'écart moyen EM est fortement sensible aux données aberrantes (voir Tableau ci-dessus).
Ecart-type σ [WIK4] :
Pour n données xi quelconques, l' écart-type est la quantité : σ = ( (1/n) ∑i[ (xi - MA)2 ] )(1/2) = ( (1/n) ∑i[ xi2] - MA2 )(1/2)
où MA est la moyenne arithmétique des données xi.
L'écart-type est à utiliser lorsque l'on cherche à calculer la moyenne quadratique des écarts à la moyenne arithmétique.
On a la relation : EM ≤ σ
L' écart-type σ est fortement sensible aux données aberrantes (voir Tableau ci-dessus). Il ne doit être calculé que sur une distribution normale ou après avoir identifié et supprimé les données aberrantes.
Ecart interquartile EI [WIK4] :
Pour n données xi quelconques, l'écart interquartile est la quantité EI = Q3 - Q1
Q1, appelé quartile inférieur (ou premier quartile), est la donnée au-dessous de laquelle se trouve 25 % des données xi lorsqu'on les classe par ordre croissant [WIK6] :
- Si le rang (1/4)(n + 3) est entier, alors Q1 = x(1/4)(n + 3)
- Si ce rang se termine par 0,25 alors Q1 = (1/4)(3 xinf + xsup)
- Si ce rang se termine par 0,50 alors Q1 = (1/2)(xinf + xsup)
- Si ce rang se termine par 0,75 alors Q1 = (1/4)(xinf + 3 xsup)
Q3, appelé quartile supérieur (ou troisième quartile), est la donnée au-dessous de laquelle se trouve 75 % des données xi lorsqu'on les classe par ordre croissant [WIK6] :
- Si le rang (1/4)(3 n + 1) est entier, alors Q3 = x(1/4)(3 n + 1)
- Si ce rang se termine par 0,25 alors Q3 = (1/4)(3 xinf + xsup)
- Si ce rang se termine par 0,50 alors Q3 = (1/2)(xinf + xsup)
- Si ce rang se termine par 0,75 alors Q3 = (1/4)(xinf + 3 xsup)
avec xinf = xrang entier inférieur
et xsup = xrang entier supérieur
L'écart interquartile EI est robuste aux données aberrantes (voir Tableau ci-dessus) et doit être préféré à l'étendue e, l'écart moyen EM et l'écart-type σ.
F4.4. Statistiques trompeuses
La statistique, comme toute autre technique, n'est pas toujours manipulée avec soin, discernement et bonne foi.
Elle fait l'objet de pièges, d'évidences trompeuses et même d'arnaques.
Echelle trompeuse :
Certains graphiques sont présentés selon une échelle verticale linéaire ne commençant pas à zéro, ou logarithmique ou totalement manquante. Dans les trois cas, si on ne fait pas bien attention à l'échelle, l'interprétation de la variable représentée peut être erronée.
La bonne définition :
Les statistiques calculées sur une variable n'ont un sens que relativement à sa définition.
Exemple [INS][WIK8][MON][JAI] : en mars 2017, le nombre de chômeurs en France métropolitaine était de 2,7 millions selon l'Insee et de 3,7 millions selon le Pôle Emploi. D'où vient cet écart ?
Pour l'Insee, un chômeur est officiellement une personne "active inoccupée" (i.e. âgée de 15 ans ou plus, sans emploi, en recherche active d'emploi et disponible sous deux semaines), ce qui exclut les personnes dites "inactives" (jeunes de moins de 15 ans ; étudiants ; retraités ; personnes en formation ; personnes découragées ; femmes avec enfants en bas âge, non disponibles rapidement ; personnes en incapacité de travailler ; etc.).
Pour le Pôle Emploi, un chômeur est une personne inscrite auprès d'une agence, sans emploi et en recherche active d'emploi (catégorie A).
20 % des chômeurs recensés par l'Insee ne sont pas inscrits à Pôle Emploi (personnes en fin de droits, personnes radiées pour motif administratif, etc.). Inversement, 40 % des chômeurs inscrits à Pôle emploi ne sont pas recensés par l'Insee, souvent pour bénéficier de certaines mesures.
Le taux de chômage est alors défini comme le ratio entre le nombre de chômeurs et le nombre d'actifs, ce dernier étant la somme du nombre d'actifs occupés et du nombre de chômeurs.
En 2022, selon l'enquête Insee, l'emploi se répartit comme suit : 68,7 % d'actifs occupés, 5,3 % d'actifs inoccupés (chômeurs) et 26,0 % d'inactifs [UNE], le taux de chômage étant de 7,2 %
Pourcentages cumulés :
Lorsqu'on cumule des hausses et des baisses en pourcentages, une perception multiplicative des pourcentages s'impose.
Exemple [DEL2] : un prix augmente de 15 % puis baisse de 6 %. Quelle est la variation de prix en pourcentage ? La réponse n'est pas +9 %
Il faut en effet multiplier le prix par 1,15 puis par 0,94, ce qui donne 1,081 et correspond à une hausse de 8,1 %
A noter que l'opération inversée "baisse de 6 % puis augmentation de 15 %" donne le même résultat, la multiplication étant commutative.
Pourcentage et valeur absolue :
Une grandeur peut diminuer en pourcentage chaque année en même temps qu'elle s'accroît en valeur absolue.
Exemple [DEL2] : Un membre du gouvernement assure que l'augmentation du déficit qui était de 15 % l'année dernière a été ramenée à 14 % cette année. L'opposition prétend au contraire que le déficit qui était de 15 milliards d'euros l'année dernière a encore augmenté cette année de plus d'un milliard d'euros. Qui a raison ?
Les 15 milliards d'euros du déficit de l'année dernière correspondent à 15 % du déficit initial (d'il y a deux ans). Celle-ci était donc de 100 milliards d'euros. L'année dernière, le déficit est ainsi passé de 100 milliards à 115 milliards. Si, comme l'indique la première affirmation, l'augmentation du déficit a été de 14 %, cette année, l'augmentation a donc atteint 14 % de 115 milliards, soit 16,1 milliards. C'est bien conforme à la deuxième affirmation selon laquelle le déficit a augmenté de plus d'un milliard. Les deux affirmations sont parfaitement compatibles.
La cause commune cachée :
Une confusion est fréquemment faite entre corrélation de facteurs (liés souvent par une cause commune) et causalité de faits (signifiant relation de cause à effet).
Exemple 1 [ANI] : une personne qui a le diabète va avoir un taux de sucre élevé et ressentir une faim excessive. Les deux facteurs sont liés et proviennent d'une même cause qu'est la maladie du diabète. Mais le taux de sucre élevé n'entraîne pas le sentiment de faim excessive, et vice versa. Ce sont des faits liés mais pas par une causalité.
Exemple 2 [TER] : les gens qui chaussent des souliers d'une taille supérieure à 45 commettent trois fois plus de meurtres que ceux qui chaussent entre 40 et 42. Cela signifie-t-il que les grands souliers induisent des comportements meurtriers ? La corrélation réelle est en fait liée au sexe : il se trouve que les comportements meurtriers se retrouvent principalement dans les individus de sexe masculin.
Loi des petits nombres :
La loi des petits nombres pousse les individus à croire qu'un petit nombre d'observations peut refléter fidèlement la population générale.
Exemple 1 [ANI] : si on compte à une réunion 70 % de femmes et qu'on utilise cette proportion de 70 % pour deviner le nombre de femmes dans le monde, cette généralisation est fausse car elle n'est pas représentative de la réalité ni du hasard de l'échantillon.
Exemple 2 [ANI] : ce n'est pas parce que nous avons guéri grâce à un remède de grand-mère que celui-ci fonctionne réellement et pour toute la population. C'est pour cela qu'en médecine de nombreux tests sont réalisés afin de savoir si oui ou non un traitement a un effet bénéfique.
Paradoxe du nombre moyen d'enfants :
"Prendre une famille au hasard" et "prendre un enfant au hasard" n'est pas la même chose.
Exemple [DEL2] : Une enquête exhaustive menée dans une ville indique que les familles ayant des enfants de moins de 18 ans se répartissent de la manière suivante : 10 % de familles à 1 enfant, 50 % à 2 enfants, 30 % à 3 enfants, 10 % à 4 enfants. Le nombre moyen d'enfants par famille (parmi celles qui ont des enfants) est donc de (10 + 100 + 90 + 40)/100 = 2,4.
Pour contrôler cette statistique, les autorités administratives procèdent à un sondage. On interroge 1000 enfants de moins de 18 ans soigneusement pris au hasard et on leur demande combien il y a d'enfants dans leur famille, eux compris. En faisant la moyenne des réponses, on obtient 2,67 ! Pourquoi cet écart si important avec les 2,4 de la statistique qui prenait en compte toutes les familles ayant des enfants ?
La réponse tient dans le fait qu'en interrogeant des enfants au hasard, vous interrogerez 4 fois plus d'enfants des familles à 4 enfants que vous n'en interrogerez dans les familles à 1 enfant, ce qui fausse la moyenne. S'il y a 1000 familles, il y aura 100 enfants uniques, 1000 enfants appartenant à une famille de 2 enfants, 900 enfants appartenant à une famille de 3 enfants, 400 enfants appartenant à une famille de 4 enfants. Au total, les réponses données par ces 2400 enfants conduiront au résultat de 2,666... enfants par famille.
Le sondage effectué n'évalue pas le nombre moyen d'enfants d'une famille prise au hasard, mais le nombre moyen d'enfants qu'on trouve dans la famille d'un enfant pris au hasard.
Paradoxe de Simpson :
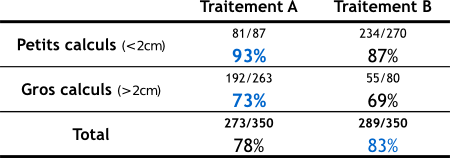
Un phénomène observé dans plusieurs groupes de données peut s'inverser lorsque les groupes sont rassemblés. Si l'on veut obtenir des conclusions sensées, l'agrégation des résultats doit respecter certaines règles d'homogénéité [DEL2].
Exemple [WIK7][SCI][DEL1] : Un patient est atteint de calculs aux reins. Son médecin lui propose deux alternatives : le traitement A et le traitement B. Pour l'aider à faire son choix, le médecin l'informe qu'une étude a été menée sur 700 patients. La moitié d'entre eux (soit 350) ont reçu le traitement A pour lequel on constate 273 guérisons (soit 78 % des cas), et les autres le traitement B pour lequel on constate 289 guérisons (soit 83 % des cas).
On sait également qu'il y a deux types de calculs : les petits et les gros (voir petit tableau ci-dessus).
- Le traitement A est un succès dans 81 cas sur 87 pour les petits calculs (soit 93 % des cas) et dans 192 cas sur 263 pour les gros (soit 73 % des cas).
- Le traitement B est un succès dans 234 cas sur 270 pour les petits calculs (soit 87 % des cas) et dans 55 cas sur 80 pour les gros (soit 69 % des cas).
Dans les deux cas (petits ou gros calculs), le traitement A est plus efficace, alors que pour le résultat global, le traitement B est plus efficace.
Ce qui crée le paradoxe, et l'impression erronée que B est globalement plus efficace, c'est que le traitement A a été donné beaucoup plus souvent pour les gros calculs, qui sont plus difficiles à soigner.
Pour se produire, le paradoxe nécessite deux conditions :
- existence d'une variable souvent cachée (appelée facteur de confusion) qui influe significativement sur le résultat final. Dans cet exemple, la taille des calculs influe sur la probabilité de succès du traitement.
- distribution hétérogène de l'échantillon étudié. Le traitement A est en effet plus souvent donné sur les gros calculs et le B sur les petits.
En sciences, on réalise des expériences "randomisées", qui permettent d'assurer une distribution homogène : par exemple si vous avez des calculs rénaux et que vous participez à une expérience pour comparer les traitements, on vous assigne au hasard le traitement A ou B, sans que la taille des calculs influe sur la décision. On gomme ainsi l'hétérogénéité de distribution, et le paradoxe disparaît : le traitement A sera bien vu comme étant le meilleur [MAT].
Lorsque le paradoxe de Simpson se produit, une des solutions pour le gommer est de rendre la distribution homogène en modifiant les effectifs dans chaque groupe de données tout en conservant les pourcentages. Dans la ligne "Petits calculs", le rapport 81/87 peut être remplacé par 251,38 /270 donnant le même pourcentage 93 %. Dans la ligne "Gros calculs", le rapport 55/80 peut être remplacé par 180,81 /263 donnant le même pourcentage 69 %. La ligne "Total" donne alors un rapport de 443,38 /533 = 83,17 % pour le traitement A et de 414,81 /533 = 77,83 % pour le traitement B, ce qui confirme que la traitement A est le meilleur.
|
Démonstration arithmétique [DEL1] : Si on note A, B, C, D les quatre nombres successifs de la ligne "Total", a,b,c,d ceux de la ligne "Petits calculs" et a', b', c', d' ceux de la ligne "Gros calculs", alors on a les relations suivantes : A = a + a' ; B = b + b' ; C = c + c' ; D = d + d' A/B < C/D ; a/b > c/d ; a'/b' > c'/d' L'étonnement vient du fait que l'on croit que la double inégalité { a/b > c/d et a'/b' > c'/d' } entraîne { A/B > C/D }, ou encore avec seulement les petites lettres : { (a + a')/(b + b') > (c + c')/(d + d') } Mais dans les faits, les trois inégalités peuvent parfois être vraies simultanément sur le plan arithmétique. Lorsque les données ont même effectif à l'intérieur de chaque groupe (b = d et b' = d') ou entre groupes (b = b' et d = d'), le paradoxe de Simpson ne peut pas se produire, la double inégalité { a/b > c/d et a'/b' > c'/d' } entraînant toujours { A/B > C/D }. |
F4.5. Sources relatives aux statistiques :
[ANI] Animafac, Les pièges de l'utilisation des chiffres.
[BIB] Bibm@th.net, Diverses moyennes.
[CAN1] Statistique Canada, Mesures de la tendance centrale.
[CAN2] Statistique Canada, Mesures de la dispersion.
[DAN] Gérard Danaguezian, Attention, statistiques !, Survey Magazine.
[DEL1] Jean-Paul Delahaye, L'embarrassant paradoxe de Simpson, Pour la Science, n 429 de juillet 2013.
[DEL2] Jean-Paul Delahaye, Déjouer les pièges des statistiques, Pour la Science, Hors-Série n 98 de février-mars 2018.
[INS] Insee, Tout demandeur d'emploi n'est pas forcément chômeur.
[JAI] Virginie Jailloux, Définition et mesure du chômage, Melkior.
[KHA] Khan Academy, Identification des valeurs aberrantes avec la règle 1,5 x écart interquartile
[MAT] Johan Mathieu, Le paradoxe de Simpson.
[MON] Le Monde, Chômage : pourquoi les chiffres de l'Insee et de Pôle emploi diffèrent.
[SCI] Science étonnante, Le paradoxe de Simpson.
[TER] Marc Tertre, Pourquoi faut-il se méfier des statistiques ?, Le Club de Mediapart.
[UNE] Unédic, Comprendre le halo du chômage.
[WIK1] Wikipedia, Moyenne.
[WIK2] Wikipedia, Moyenne d'ordre p.
[WIK3] Wikipedia, Discussion : Moyenne d'ordre p.
[WIK4] Wikipedia, Indicateur de dispersion.
[WIK5] Wikipedia, Donnée aberrante.
[WIK6] Wikipedia, Quartile.
[WIK7] Wikipedia, Paradoxe de Simpson.
[WIK8] Wikipedia, Chômage en France.
[WIK9] Wikipedia, Médiane pondérée.

F5.1. Définition :
Dans une société de consommation poussée à outrance, on assiste à une marchandisation de l'ensemble de la société. L'information devient une marchandise, soumise aux lois du marché et de la concurrence, de même que les programmes télé, le cinéma, les productions de films et les médias en général.
Pour capter l'audience dans ce contexte hautement concurrentiel, les médias ont recours à différents moyens comme le sensationnalisme, la polémique et parfois même les fausses nouvelles.
La violence est également un de ces moyens, donnant naissance à ce qu'on appelle la violence médiatique qui est, par définition, la violence humaine montrée ou suggérée par les médias, qu'elle soit verbale, physique, sexuelle ou psychologique.
F5.2. La violence humaine :
L'animal ne cherche pas à tuer ou à faire souffrir. Il tue pour se nourrir, se reproduire ou défendre son territoire. Il n'est ni pacifique, ni cruel et n'agit jamais avec excès [GAN].
Même un chat jouant avec une souris jusqu'à la mort ne cherche pas à causer de la souffrance. Il ne fait que s'entraîner afin d'affiner ses compétences de chasse.
L'être humain est aussi un animal, mais un animal de la démesure. Il se distingue des animaux par l'importance anatomique et fonctionnelle de son cerveau [GAN], notamment le néocortex dévolu à la pensée, à l'imagination et à l'anticipation, qui lui permet d'explorer et d'exploiter un milieu de plus en plus étendu.
Depuis le début de l'humanité, il y a environ deux millions d'années, l'être humain est inventif avec un côté explorateur, manipulateur, conquérant et agressif. Ce caractère foncièrement créatif l'arrache à la nature et le fait entrer dans l'excès et la transgression. Il devient alors ingénieux en matière de violence, de torture et d'horreur, renforcés par son animalité primitive sous forme de fête, sacrifice, cruauté et orgie guerrière [GAN].
Ainsi, le néocortex, siège de nos capacités cognitives supérieures, stimule notre tendance à explorer et à posséder. La violence humaine résulte de cette quête naturelle d'expansion et de contrôle.
Aujourd'hui, l'homme moderne n'est pas plus violent que dans le passé. Les guerres sont devenues de plus en plus meurtrières au 20e siècle, mais elles se raréfient. La violence criminelle est en régression depuis le 19e siècle. Elle apparaît cependant pire qu'autrefois parce que nous appréhendons les phénomènes criminels avec des normes différentes de celles utilisées dans le passé, étant habitués à une sécurité de plus en plus large [GAN].
Ainsi, la diminution de la violence est un phénomène massif et incontestable. Mais il peut y avoir des périodes de rechute, de recul, de régression. L'homme se civilise mais il ne change pas en profondeur. Les pulsions, les frustrations, les tentations violentes demeurent [PIN].
La violence est un fait universel. La sagesse consiste à l'assumer plutôt qu'à la refouler [GAN]. Mais la sagesse consiste aussi à découvrir que tout conflit est bon dès lors qu'il fait apparaître une vérité, notamment qu'on est obligé de s'accorder pour vivre et que le conflit n'a pas besoin d'être violent pour cela [MIC].
Svâmiji disait : "L'animal est soumis à la nature. L'homme lutte contre la nature. Le sage réalise l'unité avec la nature en l'accompagnant dans son mouvement."
F5.3. Formes de violence médiatique :
La liste alphabétique suivante donne les principales formes de violence médiatique sur l'être humain, allant de la simple gêne à la violence extrême.
F5.4. Controverse :
Beaucoup de personnes ne croient pas aux effets de la violence médiatique. Il y a six raisons à cela [COU] :
F5.5. Conséquences :
Sur l'être humain, les effets de la violence médiatique sont surtout ceux des images violentes (effusion de sang, coups, torture, tuerie, bombardements, accidents de la route, suicide, viol, etc.).
Sur ce sujet, plus de 50 ans de recherches scientifiques montrent qu'une exposition prolongée aux images violentes rend davantage violent, augmente la peur de devenir soi-même victime et diminue le sentiment de sympathie à l'égard des victimes de violences dans la vie réelle [COU][WIK9].
Sur l'enfant et l'adolescent, les effets de la violence médiatique sont les suivants [CBS] :
- De 0 à 2 ans : forte vulnérabilité aux effets sonores (bruits et cris).
- De 2 à 7 ans : vulnérabilité à la violence intense, banalisée, antisociale ou gratuite.
- De 7 à 12 ans : vulnérabilité à la violence intense, banalisée, antisociale ou intellectuelle.
- De 12 à 18 ans : vulnérabilité à la violence antisociale ou spirituelle.
Les programmes les plus nocifs pour les jeunes sont les films violents, y compris certains dessins animés, ainsi que les infos des journaux télévisés qui font montre de réalisme. L'impact le plus important est obtenu par l'association de la violence avec des images érotiques [KUC].
La représentation de la violence a encore plus d'impact négatif lorsque [SEN4] :
- Elle est représentée comme justifiée ou récompensée ;
- Les protagonistes violents sont attractifs ou héroïques ;
- Les conséquences pour les victimes sont minimisées ;
- Le spectateur est jeune ou prédisposé à l'agressivité.
A noter également [KUC] :
- Le nombre des émissions pour la jeunesse, surtout de bonne qualité, semble insuffisant (moins de 10 %) ce qui incite les jeunes à regarder des émissions pour adultes totalement inadaptées pour leur âge.
- Certains garçons à caractère agressif s'identifient plus facilement aux héros combatifs dont ils reproduisent le comportement dans la réalité comme dans la fiction qu'ils ont regardé (effet mimétique).
- A la télévision américaine, 20 à 25 actes violents par heure sont diffusés dans les programmes pour enfant.
- A la télévision canadienne, les relations sexuelles entre partenaires non mariés sont présentées 24 fois plus que celles entre conjoints [NIH].
F5.6. Conclusions :
Le remède à la violence médiatique consiste à trouver un meilleur équilibre entre producteurs d'images violentes et consommateurs. Cela implique principalement les acteurs suivants [COU] :
F5.7. Sources relatives à la violence médiatique :
[ART] ARTE Radio, Prise de son : les 15 erreurs du débutant.
[BEN] Abdellatif Bensfia, "François HEINDERYCKX (2003), La malinformation. Plaidoyer pour une refondation de l'information", Communication, Vol. 23/2 | 2005, 259-265..
[BIL] Philippe Bilger, Pourquoi le son français est-il si mauvais ?.
[BOU] Marie-Claude Bourdon, Médias culture et violence.
[CBS] CBSC, Canadian Broadcast Standards Council, Classement des émissions en fonction de la violence - Guide de référence.
[CLE] CLEMI, Le centre pour l'éducation aux médias et à l'information, Ecrans et violence.
[CNR] CNRTL, Centre National de Ressources Textuelles et Lexicales, Sexisme.
[COU] Courbet D. & Fourquet-Courbet M.P. (2014), "L'influence des images violentes sur les comportements et sur le sentiment d'insécurité chez les enfants et les adultes", Rapport Technique de Recherches, Université d'Aix-Marseille, Institut de Recherche en Sciences de l'Information et de la Communication IRSIC.
[CSA] CSA - Conseil supérieur de l'Audiovisuel, Réflexion sur les émissions dites "de téléréalité".
[FLA] Jean-Yves Flament, Téléréalité et idéologie.
[FMV] Fondation Marie-Vincent, Qu'est-ce que la violence sexuelle ?.
[FRI] France Inter, Algorithmes : les meilleurs amis des climatosceptiques.
[GAG] Christophe Gagne, "Un bon clash pour faire le buzz", Corela, 19-2 | 2021.
[GAN] René-François Gagnon, Cinq conceptions de la violence quotidienne, Mémoire 1999, Université Laval.
[GDC] Gouvernement du Canada, Ravaler sa douleur - Etude des liens entre l'anorexie, la boulimie et la violence contre les femmes et les filles.
[GDQ] Gouvernement du Québec, Le sexe dans les médias, Editions du Conseil du statut de la femme.
[GOU] Vincent Goulet, "Violence et médias", séances du Réseau Thématique n 37 "Médias" du 3e congrès de l'Association Française de Sociologie, Paris, 14-17 avril 2009.
[HIL] David Hiler, Réchauffement climatique : comprendre ceux qui n'y croient pas, Le Temps.
[KUC] Corinne Kucharscki, Jean-Luc Saladin, Daniel Godefroy et Matthieu Blondet, La télévision nourrit la violence, Reporterre - Le média de l'écologie.
[LER] Pierre Leroux et Philippe Riutort, Intégrer les politiques aux divertissements.
[LOO] Joséphine Loock, Violence institutionnelle de l'administration publique.
[MAT] Philippe Mathieu, Pour une histoire et une esthétique de l'écran fragmenté au cinéma, Thèse 2010, Université de Montréal.
[MCC] Ministère de la Culture et de la Communication, La violence à la télévision.
[MDT] Ministère du travail, La protection contre les discriminations.
[MIC] Yves Michaud, La violence apprivoisée.
[NIH] NIH, National Library of Medicine, Les répercussions de l'usage des médias sur les enfants et les adolescents.
[PAG] PagesJaunes/PagesConseil/Droit/, Atteinte à la dignité.
[PER] Perplexity, le moteur d'Intelligence Artificielle développé par Perplexity AI.
[PIN] Steve Pinker, La diminution de la violence dans le monde est un phénomène massif et incontestable, Libération.
[RFI] RFI, Les ados et le sexe sur Internet : attention danger!.
[RIM] Pierre Rimbert, Interdire l'information en continu ?, Le Monde diplomatique.
[SEN2] Sénat, Enfants et publicité télévisuelle.
[SEN3] Sénat, L'audiovisuel à l'ère du numérique.
[SEN4] Sénat, Violence dans les médias : quelles conséquences sur les enfants et la société ?.
[SIX] Nicolas Six, Pourquoi les dialogues sont-ils parfois aussi inaudibles dans les films et les séries ?, Le Monde.
[TOU] La Toupie, Toupictionnaire.
[TRO] Pauline Trouillard, "Atteinte à la dignité humaine et autres contenus toxiques à la télévision française : le Conseil d'Etat a t-il ouvert la boîte de Pandore ?", La Revue des droits de l'homme, 24 | 2023.
[WIK2] Wikipedia, Cyberharcèlement.
[WIK3] Wikipedia, Perversion.
[WIK4] Wikipedia, Violence conjugale.
[WIK5] Wikipedia, Violence psychologique.
[WIK6] Wikipedia, Télé poubelle.
[WIK7] Wikipedia, Téléréalité.
[WIK8] Wikipedia, Violence policière.
[WIK9] Wikipedia, Education parentale.
[WIK10] Wikipedia, Entertainment Software Rating Board.
[YAP] yapaka.be, Les images violentes ne sont pas nécessairement celles que l'on croit.
Les attaques par email, également appelées attaques de phishing, sont de plus en plus courantes et rusées [CYM][CYS][KEP].

F6.1. Structure d'un email :
Un courrier électronique (ou "email" ou "electronic mail" ou "courriel") est un message écrit transmis via un réseau informatique, d'une boîte aux lettres électronique à une ou plusieurs autres, permettant une communication quasi-immédiate entre un expéditeur et un ou plusieurs destinataires.
L'email utilise des protocoles comme SMTP pour l'envoi et POP/IMAP pour la réception.
Un email complet se compose de plusieurs parties :
Une adresse email a une syntaxe définie principalement par la norme RFC 5322 comme suit [CHA][PER] :
|
A noter qu'il est fortement recommandé d'utiliser des minuscules dans les adresses email. Le domaine de l'adresse email (après le "@") ne pose pas problème car il est insensible à la casse (minuscule ou majuscule) conformément aux normes DNS (Domain Name System). En revanche, la partie locale (avant le "@") reste sensible à la casse, et l'utilisation de majuscules dans cette partie, bien que techniquement autorisée, peut entraîner plusieurs risques, principalement pour l'expéditeur : 1. Des erreurs de saisie. Un destinataire peut fournir une version incorrecte de son adresse en omettant les majuscules, ou un expéditeur peut mal retranscrire une adresse contenant des majuscules. 2. Des échecs de livraison. Bien que rares, certains serveurs traitent encore la partie locale des adresses email comme sensible à la casse, ce qui peut empêcher la réception des emails. |
F6.2. Réception d'un email douteux :
Quand on reçoit un email douteux, il n'y a pas de risque majeur à simplement ouvrir l'email.
Selon la configuration du client de messagerie du destinataire, l'expéditeur peut seulement recueillir les données techniques suivantes concernant le destinataire :
1. Adresse email. Exemple : jane.smith@company.com
2. Type d'appareil. Exemples : ordinateur de bureau (Desktop), mobile (Mobile), tablette (Tablet)
3. Adresse IP (IP = Internet Protocol) : identifiant unique attribué à chaque appareil connecté au réseau Internet. Exemple (site officiel de l'Université de Bourgogne : www.u-bourgogne.fr) : 194.199.107.34
4. Géolocalisation approximative (position estimée de l'appareil connecté à Internet en utilisant son adresse IP). Exemple (pour www.u-bourgogne.fr) : France, Bourgogne-Franche-Comté, Côte-d'Or, Dijon, coordonnées GPS approximatives : 47.3220 N, 5.0415 E
5. Système d'exploitation (OS = Operating System). Exemples : Windows 10 64-bits, macOS 11.5.2, Ubuntu Linux 64-bits, Android 13
6. Type et version du navigateur Web. Exemples : Chrome 118.0.5993.88, Firefox 118.0.2
7. Moteur de rendu du navigateur Web. Exemples : Moteur HTML (Blink, Gecko, Webkit), Moteur 3D pour jeux vidéo et logiciels 3D, Moteur pour synthèse d'image 3D
8. Langue préférée du navigateur Web. Exemples : fr-FR, en-US
9. Type de client de messagerie. Exemples : Gmail, Outlook 365, Apple Mail
10. Date et heure d'ouverture de l'email. Exemple : 2024-10-02 14:32:22 UTC+2
Ces données peuvent être utilisées ultérieurement par le cybercriminel pour des attaques plus ciblées.
F6.3. Structure d'un email douteux :
Les critères permettant d'identifier un email douteux sont les suivants [CHA][PER] :
- Adresse d'expéditeur dont la partie locale ou le domaine contient une des anomalies typiques suivantes :
- une série de lettres ou de chiffres aléatoires (exemples : contact-entreprise8765@gmail.com, contact-entreprise@gmail-5g78.com
- une inversion entre deux caractères (notamment "l" et "i majuscule", "l" et "1", "O" et "0"). Exemples : john.d0e@example.com, help@paypaI.com, support@paypa1.com, info@micros0ft.com
- des tirets multiples (exemple : help@secure-paypal-login.com)
- une seule faute d'orthographe qui échappe à l'attention (exemple : john.does@example.com, help@amazom.com)
- une extension de domaine inhabituelle, notamment certaines extensions gratuites comme .tk, .ml, .ga (exemple : john.doe@example.tk)
- Email inattendu. Exemple : facture ou colis non commandé.
- Email incohérent par rapport aux communications habituelles de l'expéditeur :
- au niveau adresse. Exemple : email prétendant venir d'une banque et utilisant une adresse Gmail.
- au niveau format. Exemples : logo, en-tête, couleurs ou disposition différentes.
- au niveau contenu : absence de personnalisation. Exemple : "Cher client, nous avons détecté une activité suspecte sur votre compte. Veuillez cliquer ici pour le sécuriser. Cordialement. L'équipe de sécurité."
- Contenu avec image à la place du texte (qui empêche la détection de l'email par les filtres de courrier indésirable).
- Fautes d'orthographe ou de grammaire. Exemple : "Nous vous remercion de votre confience."
- Mention d'offre merveilleuse ou de promesse de gains faciles. Exemple : "Félicitations. Vous avez gagné un bon de 200 euros chez Amazon ! Cliquez ici pour le réclamer maintenant."
- Demande d'information personnelle ou sensible. Exemple : "Merci de nous communiquez votre numéro de carte bancaire pour vérification."
- Demande de déactivation de l'antivirus, pare-feu ou toute autre mesure de sécurité pour ouvrir une pièce jointe ou visiter un site.
- Ton insistant, urgent ou menaçant. Exemple : "URGENT : votre compte sera bloqué dans 24 heures si vous ne répondez pas immédiatement."
- Pièce jointe avec format inhabituel (.exe, .zip, .scr, etc.). Exemple : "Veuillez ouvrir le fichier facture_urgente.exe ci-joint pour vérifier votre solde impayé."
- Lien pointant vers une adresse web douteuse.
F6.4. Ce qu'il ne faut pas faire :
- Faire totalement confiance au vu de la seule adresse de l'expéditeur. Elle peut être usurpée (voir Points de contrôle).
- Cliquer sur un lien ou sur une image
- Afficher les images qui ne sont pas chargées
- Ouvrir ou télécharger une pièce jointe
- Répondre à l'email ou le transmettre
- Communiquer des informations personnelles ou sensibles (coordonnées bancaires, mot de passe, etc.)
- Contacter l'expéditeur à partir d'informations fournies dans l'email (téléphone, email, etc.)
- Ignorer un avertissement de sa messagerie ou de son antivirus signalant un email potentiellement frauduleux.
F6.5. Ce qu'il faut faire :
- Garder son calme
- Prendre le temps de vérifier la légitimité de l'email (adresse de l'expéditeur, format et contenu de l'email)
- Vérifier les liens sans cliquer dessus (en passant la souris pour voir l'URL réelle)
- Copier une partie de l'email (comme l'objet ou des phrases-clefs) et faire une recherche sur Internet pour voir si d'autres personnes ont signalé cet email comme frauduleux
- Conserver des éléments de preuve par des captures d'écran
- Supprimer l'email
- Changer la police par défaut du client de messagerie pour faire la distinction nette entre un "l" et un "i majuscule" : passer en Times New Roman, ou Georgia ou Verdana par exemple.
F6.6. Points de contrôle pour identifier un email usurpé [CHA][PER] :
1. Visualiser le détail de l'en-tête de l'email, soit par un clic droit sur l'email (sans l'ouvrir et en sélectionnant "Montrer l'original" ou "Afficher le code source"), soit en ouvrant l'email (et en sélectionnant le menu ad'hoc).
Exemples de menus (en ouvrant l'email) : Orange (Détails - En-tête complet), Gmail (Plus, Afficher l'original), Free (Autres actions - Montrer l'original), Windows Live Mail (Propriétés - Détails).
2. Localiser les champs suivants :
- From : indique l'adresse email de l'expéditeur.
- Return-Path ou envelope sender ou MAIL FROM : indique l'adresse email à laquelle les messages non délivrables doivent être renvoyées.
- DKIM-Signature ou DKIM-Filter ou X-DKIM-Result (champ éventuel) : indique si le message a été authentifié selon la méthode DKIM (DomainKeys Identified Mail).
- Received-SPF ou SPF ou X-Received-SPF ou X-SPF (champ éventuel) : indique si le message a été authentifié selon la méthode SPF (Sender Policy Framework).
- Received-DMARC ou DMARC-Filter ou X-DMARC-Result (champ éventuel) : indique si le message a été authentifié selon la méthode DMARC (Domain-based Message Authentication, Reporting & Conformance).
- Authentication-Results ou X-Authentication-Results (champ éventuel) : donne les résultats des différentes méthodes d'authentification effectuées par les différents serveurs (serveurs intermédiaires et serveur de réception).
3. Comparer le champ "Return-Path" avec le champ "From" : Deux cas sont possibles : 1. Les adresses email doivent être identiques, 2. Le champ Return-Path doit avoir un domaine (indiqué après "@") correspondant à un serveur connu (le vérifier en tapant ce domaine dans un moteur de recherche sur Internet).
4. Comparer le champ "DKIM-Signature" avec le champ "From" : Deux cas sont possibles : Le domaine indiqué après "d=" dans le champ "DKIM-Signature" doit être, soit identique au domaine de l'email (indiqué après "@" dans le champ "From"), soit correspondre à un serveur connu (le vérifier en tapant ce domaine dans un moteur de recherche sur Internet).
5. Examiner le champ "Received-SPF" : le statut "fail" ne doit pas apparaître.
6. Examiner le champ "Received-DMARC" : le statut "fail" ne doit pas apparaître.
7. Examiner le champ "Authentication-Results" : les statuts "dkim=fail", "spf=fail" et "dmarc=fail" ne doivent pas apparaître.
F6.7. Exemple d'en-tête d'email normal (non usurpé) [PER] :
From: "John Doe" <john.doe@example.com>
To: "Jane Smith <jane.smith@company.com>
Subject: Réunion d'équipe hebdomadaire
Date: Fri, 4 Oct 2024 09:45:21 +0200
Message-ID: <1234567890@mail.example.com>
MIME-Version: 1.0
Content-Type: text/plain; charset="UTF-8"
Content-Transfer-Encoding: quoted-printable
Return-Path: <john.doe@example.com>
Received: from mail.example.com (mail.example.com [192.0.2.1])
by inbound.company.com (Postfix) with ESMTPS id ABC123
for <jane.smith@company.com>; Fri, 4 Oct 2024 09:45:23 +0200 (CEST)
DKIM-Signature: v=1; a=rsa-sha256; c=relaxed/relaxed;
d=example.com; s=dkim;
h=from:to:subject:date:message-id; bh=...snip...; b=...snip...;
Received-SPF: pass (company.com: domain of john.doe@example.com designates 192.0.2.1 as permitted sender) client-ip=192.0.2.1; envelope-from=john.doe@example.com; helo=mail.example.com;
Authentication-Results: inbound.company.com;
dkim=pass header.i=@example.com;
spf=pass (company.com: domain of john.doe@example.com designates 192.0.2.1 as permitted sender) smtp.mailfrom=john.doe@example.com;
dmarc=pass (p=NONE sp=NONE dis=NONE) header.from=example.com
F6.8. Sources relatives au Courrier électronique douteux :
[CHA] ChatGPT, le moteur d'Intelligence Artificielle développé par OpenAI.
[CYM] cyber-malveillance.gouv.fr, Comment reconnaître un mail de phishing ou d'hameçonnage ?
[CYS] Cyber-securite.fr, Comment savoir si j'ai ouvert un mail douteux ?
[KEP] Keeper, Pouvez-vous être piraté simplement en ouvrant un e-mail ?
[PER] Perplexity, le moteur d'Intelligence Artificielle développé par Perplexity AI.
En navigant sur le web, il est essentiel de savoir identifier les adresses web douteuses, car cliquer sur un lien suspect peut exposer à des risques majeurs tels que le vol de données personnelles, les infections par des logiciels malveillants et des arnaques en ligne.

F7.1. Structure d'une adresse web :
Une adresse web (ou URL - Uniform Resource Locator) est l'adresse unique d'une ressource (page web, fichier, données, etc.) sur le réseau Internet.
Une adresse web a une syntaxe définie principalement par la norme RFC 3986 comme suit [CHA][PER] :
F7.2. Structure d'une adresse web douteuse :
Les critères permettant d'identifier une adresse web douteuse sont les suivants [CHA][PER] :
- Site à échanges non sécurisés (protocole http au lieu de https) lorsqu'il comporte un formulaire de saisie de données personnelles. A noter qu'un site purement "vitrine" en http est peu dangereux.
- Adresse web dont le domaine contient une des anomalies typiques d'une adresse email douteuse
- Adresse IP provenant d'un email non sollicité ou d'une source inconnue
- Adresse IP utilisée seule, sans contexte ou identification d'un organisme légitime
- Adresse IP spéciale qui ne devrait normalement pas apparaître sur l'Internet public. La liste de ces adresses est la suivante :
F7.3. Ce qu'il ne faut pas faire :
- Cliquer sur le lien.
F7.4. Ce qu'il faut faire :
- Vérifier le propriétaire de l'adresse IP ou du domaine en utilisant des outils comme WHOIS
- Analyser la réputation du site via des forums ou des sites spécialisés en cybersécurité
- Copier le lien et faire une recherche sur Internet pour voir si d'autres personnes ont signalé ce lien comme frauduleux
- Conserver des éléments de preuve par des captures d'écran
- Changer la police par défaut du client de messagerie pour faire la distinction nette entre un "l" et un "i majuscule" : passer en Times New Roman, ou Georgia ou Verdana par exemple.
F7.5. Sources relatives à l'adresse web douteuse :
[CHA] ChatGPT, le moteur d'Intelligence Artificielle développé par OpenAI.
[PER] Perplexity, le moteur d'Intelligence Artificielle développé par Perplexity AI.
Deux sujets d'intelligence artificielle (IA) sont présentés ci-dessous : les moteurs d'IA et la robotique.
F8.1. Moteurs d'IA
Les moteurs d'IA fournis par l'intelligence artificielle moderne présentent des atouts mais également des limites qui montrent que les moteurs d'IA ne peuvent pas être utilisés comme sources de vérité absolue.
Par contre, ce sont de puissants outils lorsqu'ils sont utilisés de manière critique et en complément de l'expertise humaine.
Examinons ces aspects plus en détail.

F8.1.1. Fonctionnement [CHA][PER] :
Tous les moteurs d'IA qui génèrent du texte construisent leur réponse mot après mot, en prédisant à chaque étape, à partir de la question posée et des données disponibles, le mot qui suit le plus probablement les mots déjà générés.
L'objectif n'est donc pas de "dire vrai", mais de "dire probable" au regard des données disponibles.
Les données disponibles proviennent de trois sources : les données apprises pendant l'entraînement (figées à la date du gel des connaissances), les données trouvées sur le web en temps réel (pour les moteurs qui y ont accès) et le contexte de la conversation en cours.
Schématiquement, les moteurs calculent ensuite en interne un score de confiance basé sur la ressemblance entre les données disponibles et leur correspondance avec la question posée.
- Si ce score dépasse un seuil jugé suffisant (seuil de décision), le moteur fournit une réponse produite de manière probabiliste, pouvant correspondre à une réponse exacte, une réponse adaptée (par interpolation ou extrapolation à partir de données voisines), ou une hallucination franche. Cependant la frontière entre ces trois types de réponse, bien que définie en interne par un score de confiance et un seuil de décision, demeure complètement opaque pour l'utilisateur.
- Dans le cas contraire, la plupart des moteurs fournissent une réponse négative ou une demande de précision afin de limiter le risque d'hallucination.
|
Conclusion : Ainsi, tous les moteurs d'IA produisent plus ou moins des hallucinations, des biais et des erreurs, impossibles à détecter directement par l'utilisateur. Il est donc impératif de recouper les informations fournies par un moteur d'IA au moyen d'une vérification croisée avec d'autres sources reconnues ou avec d'autres moteurs d'IA. Cette démarche - pilier de tout travail journalistique ou scientifique - présente un double avantage : - Elle limite efficacement les hallucinations, les biais et les erreurs. - Elle permet de sélectionner le meilleur de chaque source afin d'aboutir à une synthèse plus complète et plus fiable. A noter : - Taux de fiabilité : Toute comparaison entre moteurs d'IA fondée sur un taux de fiabilité demeure arbitraire, en raison de l'hétérogénéité des données d'entraînement et des méthodes d'évaluation. Ainsi, à ce jour, aucun benchmark robuste n'existe pour évaluer objectivement la fiabilité des réponses des moteurs d'IA. *En effet, la plupart des taux de fiabilité n'ont pas de définition unifiée et, même lorsqu'ils en ont une, l'évaluation ne couvre pas l'ensemble des moteurs. - Qualité des réponses : Les moteurs d'IA s'efforcent toujours de fournir la réponse la plus proche possible de la question posée. L'utilisateur doit donc impérativement formuler ses questions de manière claire, précise et structurée. |
F8.1.2. Atouts [CHA][PER] :
Les moteurs d'IA actuels présentent de sérieux atouts, en particulier :
F8.1.3. Limites et défauts majeurs [CHA][PER] :
Les moteurs d'IA actuels présentent des défauts majeurs et des limites intrinsèques affectant la qualité des réponses fournies. Ceux-ci s'expliquent principalement par :
- le fonctionnement probabiliste du moteur.
- la qualité, la représentativité et la fraîcheur des données d'entraînement.
- la qualité des données brutes collectées sur le Web ainsi que celle du filtrage réalisé sur ces données.
- l'absence de mécanisme de vérification interne.
- l'opacité des algorithmes (effet "boîte noire") qui favorise l'apparition et la persistance de raisonnements défaillants difficilement détectables et corrigeables.
On peut citer :
F8.1.4. Comment choisir et bien utiliser un moteur d'IA ? [CHA][PER] :
Il semblerait que les principaux acteurs de l'IA aient adopté deux stratégies distinctes en matière de moteurs d'IA :
- Google et Microsoft ont choisi de proposer des versions gratuites à la qualité perfectible, jugée suffisante pour les besoins courants grand public (moteurs Gemini et Copilot).
- Anthropic, Perplexity AI et OpenAI ont privilégié une approche axée sur la qualité, même en accès gratuit (moteurs Claude, Perplexity et ChatGPT). Claude et Perplexity excellent dans la fiabilité des réponses, tandis que ChatGPT excelle dans l'exhaustivité des réponses et sa qualité rédactionnelle et explicative. Tous trois offrent en complément une interface utilisateur intuitive et bien structurée, ainsi qu'un suivi contextuel garantissant le fil et la cohérence des échanges.
Passer à une version payante améliore par ailleurs l'expérience utilisateur et l'accès à certaines fonctionnalités supplémentaires. Mais cela ne garantit pas la résolution des défauts majeurs intrinsèques à certains moteurs d'IA, comme leur incapacité à prendre en compte tous les paramètres d'une question ou à assurer un suivi contextuel cohérent.
Par ailleurs, il est important de savoir choisir et utiliser correctement un moteur d'IA :
F8.1.5. Les facteurs clés d'un moteur d'IA [CHA][PER] :
Une expérience utilisateur optimale d'un moteur d'IA repose sur plusieurs facteurs clés :
Selon les estimations croisées de Similarweb, FirstPageSage, StatCounter et xpert.digital pour 2025-2026, le marché mondial de l'IA conversationnelle en 2026 semble se structurer autour d'une scission nette entre deux segments :
- En grand public (B2C), ChatGPT domine sans partage, porté par son avance historique et sa notoriété (65 %), devant Gemini (21 %), Perplexity (6 %), Claude (4 %) et Copilot (1 %). Gemini progresse rapidement grâce à sa distribution native dans l'écosystème Google. Perplexity s'impose comme la référence de la recherche IA. Claude et Copilot restent marginaux dans ce segment.
- En professionnel (B2B), le classement s'inverse profondément. Claude y est numéro un (32 %) devant ChatGPT (25 %), Gemini (15 %), Copilot (13 %) et Perplexity (8 %, estimation). Cette inversion s'explique par des critères de sélection totalement différents : sécurité des données, gouvernance des donnés (conformité RGPD), fiabilité sur les tâches complexes et intégration dans les workflows existants.
La leçon de ce marché est que visibilité et rentabilité racontent deux histoires différentes, un contrat entreprise pesant infiniment plus qu'un million de requêtes gratuites.
F8.2. Robotique
La robotique moderne, qu'elle soit domestique ou industrielle, présente des atouts significatifs mais reste contrainte par des dangers non négligeables.
Les risques liés aux défaillances techniques ou logicielles, ainsi que les incertitudes face à des environnements imprévus, limitent souvent l'utilisation des robots à des espaces strictement contrôlés afin de garantir la sécurité des humains.
Examinons ces aspects plus en détail.


F8.2.1. Atouts de la robotique actuelle [CHA][PER] :
La robotique actuelle présente les principaux atouts suivants :
F8.2.2. Limites et dangers [CHA][PER] :
Les principales limites et dangers de la robotique actuelle sont les suivants :
F8.2.3. Avenir de la robotique domestique [CHA][PER][PET] :
Les robots domestiques incarnent une vision d'avenir prometteuse où la technologie se met au service de l'humain pour améliorer sa qualité de vie.
Toutefois, cette vision ne pourra se concrétiser qu'à condition de concilier robustesse technique, sécurité et responsabilité sociale.
Les robots domestiques doivent, non seulement être performants et fiables sur le plan technique, mais aussi être intégrés de manière réfléchie et harmonieuse dans nos foyers. Cette intégration doit tenir compte de leurs impacts sociaux, psychologiques et éthiques.
Si ces défis complexes sont relevés avec succès, les robots domestiques pourraient devenir des partenaires essentiels de notre quotidien. Dans le cas contraire, les risques et questionnements qu'ils suscitent pourraient freiner leur adoption, limitant leur avenir à des usages de niche.
F8.3. Sources relatives à l'intelligence artificielle :
[CHA] ChatGPT, le moteur d'Intelligence Artificielle développé par OpenAI.
[PER] Perplexity, le moteur d'Intelligence Artificielle développé par Perplexity AI.
[PET] Régis Petit, Contribution à l'intégration de la vision passive tridimensionnelle en robotique : suivi de contours, calibrage de caméra et commande cinématique de robot, Thèse de Docteur-Ingénieur, INPT Toulouse, 1985.
 Dernière mise à jour de la page : 8 juin 2026.
Dernière mise à jour de la page : 8 juin 2026.